
Diskussionen über Artificial Intelligence (AI) drehen sich oft um zukünftige Möglichkeiten und überzogene Produktivitätsversprechungen. Relevanter ist jedoch, was gerade jetzt passiert: Was leisten heute verfügbare AI-Werkzeuge und welche Auswirkungen hat das auf unsere Art, Softwaresysteme zu entwickeln?
Wir lesen täglich Marketingmeldungen von der „Disruption durch AI“, von „10x Produktivität“ von „AGI“ (Allgemeiner künstlicher Intelligenz), die angeblich nicht mehr lange auf sich warten lässt. Immer wieder wird spekuliert, welche Rollen und Jobs in Zukunft nicht mehr gebraucht werden. Auf technischer Seite explodiert die Anzahl von Copiloten, MCP-Servern und Agentic Systems. Es ist anstrengend und geil zugleich.
Auch wenn AI auf Marketingebene nur schwer zu ertragen scheint, ist die technische Seite interessant bis inspirierend. Je mehr man sich mit den Möglichkeiten und Werkzeugen auseinandersetzt, desto klarer wird, dass AI-gestützte Softwareentwicklung auch „nur“ Engineering ist – gleichzeitig ist der Umgang mit Werkzeugen anders, Aufgaben verschieben sich und einige Wahrheiten der Softwareentwicklung werden infrage gestellt. Ganz unaufgeregt und nüchtern lässt sich nach einigen Jahren Erfahrung feststellen: Softwareentwicklung, Systemdesign und Architektur verändern sich.
Softwarearchitektur schafft traditionell Ordnung im Komplexen – sie strukturiert, abstrahiert und investiert bewusst in das „schwer Änderbare“. Als Planungsdisziplin erfordert Architekturarbeit einen gewissen Abstand von der konkreten Implementierung und hat den Zweck, teure Fehlentwicklungen zu vermeiden. Mit Sprachmodellen, Coding Assistants und Context Engineering wird nun vieles günstiger: Prototypen entstehen in Stunden statt Wochen, Varianten lassen sich schneller umsetzen, Lösungen rascher portieren. Die Grenze zwischen „schwer“ und „leicht änderbar“ wird neu gezogen. Gleichzeitig entstehen neue Herausforderungen, denen wir uns stellen müssen.
Vibe Coding: die Einstiegsdroge
Der erste Kontakt mit AI-Tools ist wohl meist das Chatinterface eines Large Language Models (LLM). Diese Modelle geben bei Fragen gerne mal konkrete Antworten und wenn man technische Fragen stellt, entstehen auf einmal Schnittstellenspezifikationen, Teilimplementierungen oder ausführbare Skripte. Mit CLI-Tools (Command Line Integration) oder LLM-Integration in IDEs ist es verlockend, diese Lösungen direkt zu verwenden. Mit etwas Routine könnte man in einen „Flow-Zustand“ rutschen, in dem man AI-Tools eher sorglos nutzt, pragmatische Bedenken beiseiteschiebt und dafür rasche Fortschritte feiert. Vibe Coding ist geboren.
In experimentellen, risikoarmen Umfeldern kann dieses Vorgehen durchaus überzeugen und so haben viele von uns schon mal ein kleines Tool zum persönlichen Gebrauch „gevibet“. Der Fortschritt kann beim richtigen Problem beeindruckend sein, die Produktivitätsversprechen der AI Bubble wirken realistischer. Dieser erste Rausch erzeugt im Gleichschritt Anhänger der AI-Bewegung und Leute, die solch oberflächliche Entwicklungspraktiken ablehnen. Ist das tatsächlich der Kern dessen, was LLMs für die Softwareentwicklung leisten können?

Systeme modernisieren statt nur migrieren
Power-Workshops zu Modernisierung & Service-Architektur (24. - 27. November 2025, Berlin)
AI-gestützte Softwareentwicklung
Vibe Coding ist ein mentales Modell oder eine Einstellung, orthogonal zur konkreten Werkzeugwahl. Wir können Softwarelösungen auch außerhalb des AI-Kontexts schnell und ohne viel Designaufwand umsetzen. Früher haben wir es Quick Hack genannt oder auf höherer Ebene von „zufälliger Architektur“ gesprochen. Trennen wir diesen Zugang von den technischen Möglichkeiten, lässt sich ein ganzes Feld aufspannen, in dem wir professionell AI-gestützt Software entwickeln.
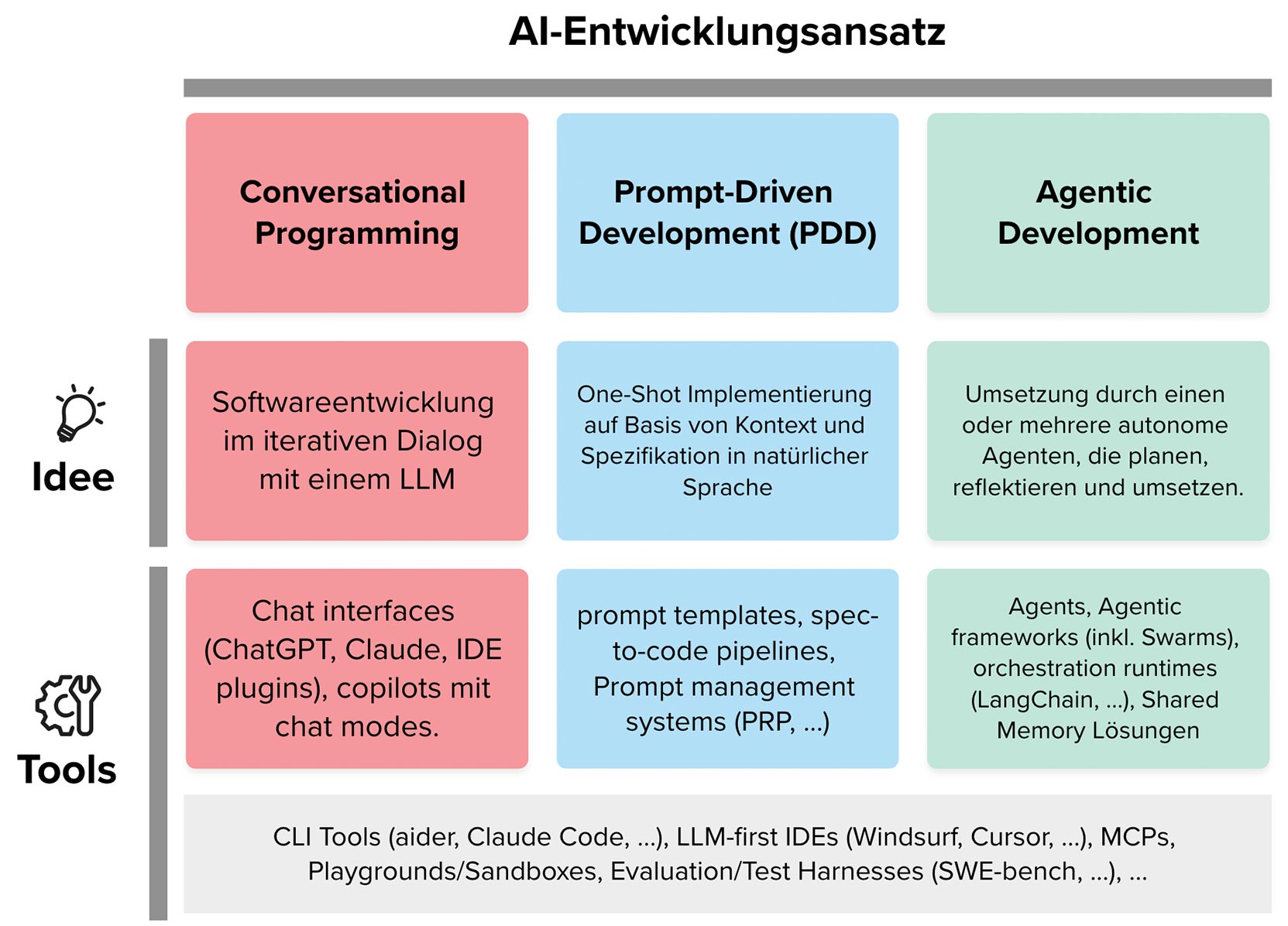
Abbildung 1 zeigt unterschiedliche Entwicklungsparadigmen, die mit LLM-Unterstützung entstehen:
-
Conversational Programming: Software wird iterativ im Dialog mit einem LLM entwickelt (z. B. ChatGPT, IDE-Plug-ins, Copilots).
-
Prompt-Driven Development (PDD): Low-Level Coding wird durch natürliche Sprachspezifikationen ersetzt. Wichtig sind Prompt-Templates, Spezifikation-zu-Code-Pipelines und Prompt-Management-Systeme.
-
Agentic Development: Entwicklung wird an autonome Agenten delegiert, die Aufgaben planen, umsetzen und orchestrieren (Agent-Frameworks, Swarm-Ansätze, Orchestration Runtimes, Shared Memory).
Komplexere Set-ups wie Product Requirement Prompts (PRPs [1]) oder Agent Swarms (z. B. Claude Flow [2] oder Archon [3]) versuchen zwar, Kernprobleme des einfacheren Conversational Programmings zu adressieren, bringen jedoch neue Herausforderungen mit sich. Wir können mit einem Konzert aus Agents z. B. einfachen Halluzinationen begegnen, bringen allerdings auch mehr Autarkie in die Entwicklung. Dadurch können inhaltsleere Dummy-Implementierungen, übersprungene Tests oder zu einfache Lösungsalternativen entstehen. Bei naiver Anwendung ist man häufig mit Erfolgsmeldungen konfrontiert, die wenig mit dem tatsächlichen Implementierungserfolg zu tun haben. Jeder Ansatz hat seinen eigenen Sweet Spot, alle haben aber Schwierigkeiten damit, sich konsistent an eine Entwicklungskultur zu halten, Tokens sparsam zu behandeln, funktionierende Lösungen zu schützen oder Daten out of the box zu schützen.
Auch der Aufwand einer Umsetzung schwankt durch den Einsatz von AI-Mitteln mehr. Gab es früher etwas Varianz im Entwicklungsaufwand zu schätzen, ist es heute schwierig zu sagen, ob eine Lösung fast gratis umgesetzt werden kann oder man nach einigen gescheiterten AI-Versuchen doch bei einer manuellen Implementierung als einziger Lösungsmöglichkeit landet.
All das erfordert nicht nur Erfahrung im Umgang mit den genannten Ansätzen und Werkzeugen, sondern auch einige neue Strategien im Umgang mit AI-gestützter Entwicklung.
Strategien für bessere AI-Entwicklung
Einige Best Practices im Umgang mit AI-Werkzeugen bilden sich mit etwas Erfahrung recht schnell heraus. In unseren Implementierungsvorhaben schneiden wir Aufgaben klein (auch jene für Agents) und nutzen evtl. vorhergehende, breitere Prompts, um Lösungsmöglichkeiten zu verstehen und das Problem zu strukturieren. Die Ergebnisse solcher frühen Prompts werfen wir meist weg. Wir arbeiten prinzipiell in Sandboxes [4], in kleinen Schritten und bereichsintensiv. Wir versuchen den Aktionsradius von LLMs über globale Regeln zu beschränken und darin auch Entwicklungskultur zu definieren. All das hat eine architektonische Komponente, wir können AI-Tools aber auch wirklich als Architekturwerkzeuge verstehen und einsetzen. Mit diesem Blickwinkel lassen sich einige Verschiebungen beobachten – ich greife in der Folge drei davon heraus. Sie sind in Abbildung 2 illustriert.
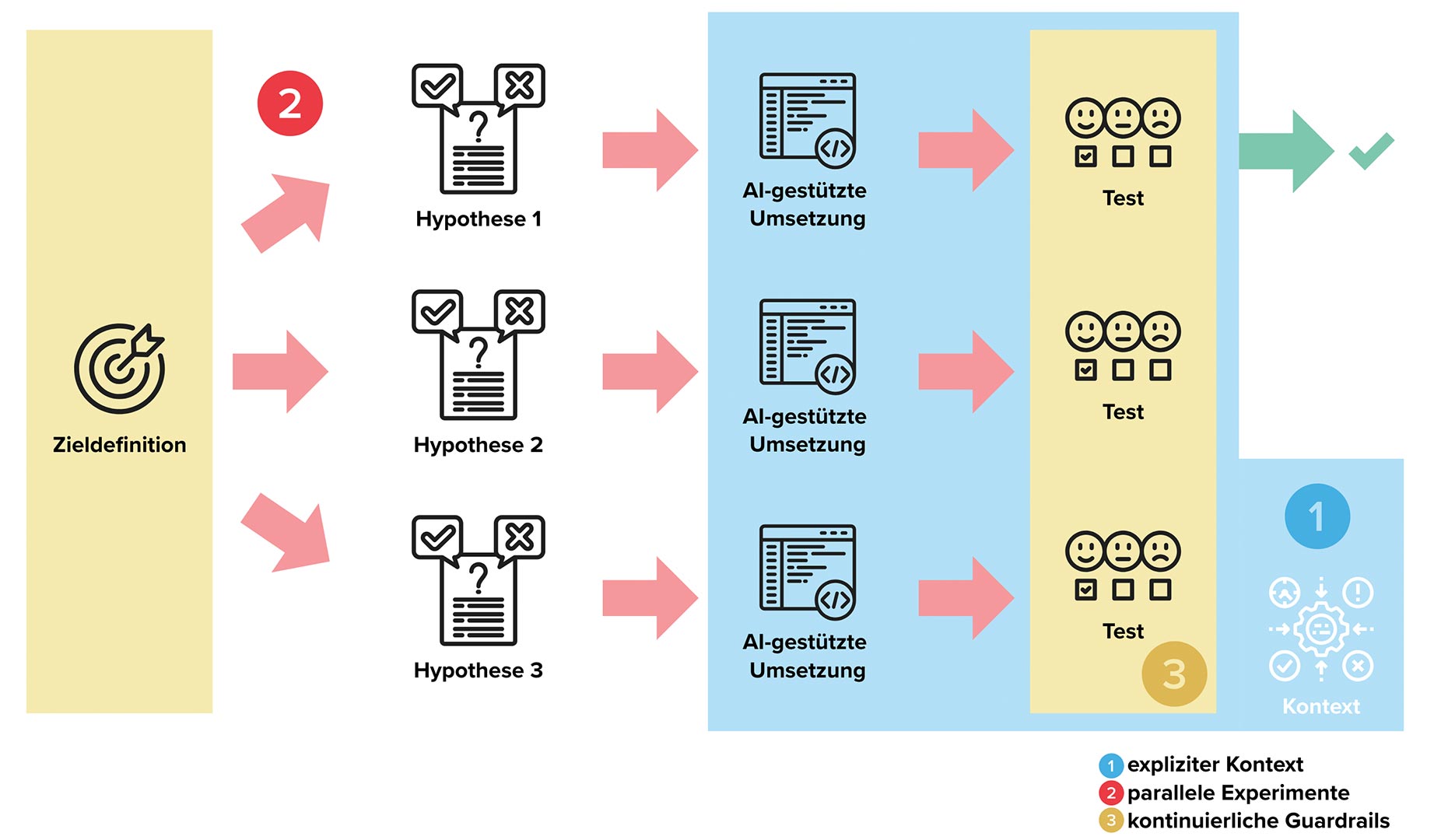
Vom impliziten zum expliziten Kontext
Wir können nicht annehmen, dass AI-Werkzeuge über gesunden Menschenverstand verfügen oder schon länger dabei sind und deshalb schon wissen, wie ein Problem in unserem Umfeld richtig gelöst wird. AI-Werkzeuge können zwar schnell generischen Code produzieren, ein großer Hebel, um architektonisch brauchbare Lösungen zu erhalten, liegt jedoch im Context Engineering [5]. Was früher implizit in Teamkulturen und Entwicklerköpfen existierte, muss maschinenlesbar werden: Wir betten Architekturprinzipien, Kommunikationsmuster oder für die Architektur wichtige Qualitätskriterien deshalb in den Kontext von LLMs ein. Von einfachen Sichtbarkeitsregeln oder dem gewollten Einsatz von Technologien können wir bis zu kodifizierten Compliance-Anforderungen gehen.
Neben einfachen Einträgen in ein agents.md-File gibt es auch größere Keulen. Wir können z. B. jede AI-gestützt entwickelte Funktion automatisch gegen regulatorische Vorgaben prüfen, die wir zuvor in einem Knowledge-Graph hinterlegt haben. So wird klar, ob personenbezogene Daten korrekt verschlüsselt sind oder ob die Auditlogs vollständig sind. Diese Explizitmachung betrifft alle Ebenen der Architektur. Service-Graphen können erlaubte Kommunikationswege dokumentieren. Architecture Decision Records (ADRs) werden zu strukturierten Daten, die LLMs verstehen und berücksichtigen können. Commit-Messages folgen Schemata, die Intentionen maschinell auswertbar machen …
Von sequenzieller zu paralleler Lösungsfindung
Das klassische Vorgehen Analyse → Design → Implementierung wird unpraktikabel, wenn Lösungen sehr schnell (prototypisch) umgesetzt werden können. Wir arbeiten deshalb intensiver mit hypothesengetriebener Entwicklung und parallelen Experimenten.
Nehmen wir an, wir beobachten immer höhere Lastspitzen in unserer Anwendung und brauchen eine Strategie, um damit umzugehen. Während wir früher viel auf Diskussions- und Analyseebene geregelt haben, können wir heute Varianten definieren, umsetzen und testen: Hilft uns horizontale Skalierung mit Kubernetes? Sollten wir einen Cache-Layer mit Redis einführen, um die Datenbanklast zu reduzieren? Können Serverless Functions für einige zentrale Endpunkte helfen?
In mehreren Projekten konnten wir solche Fragen praxisnah klären, indem wir die Hypothesen AI-gestützt umgesetzt haben, statt sie lange theoretisch zu diskutieren. Lasttests liefern anschließend belastbare Daten, die Entscheidung basiert auf Fakten, nicht auf Vermutungen.
Dieses Vorgehen birgt Vorteile auf vielen Ebenen: Um belastbare Vergleiche anzustellen, beschäftigen wir uns intensiver mit Zielsetzungen und deren Quantifizierung. Architekturrollen, die etwas umsetzungsferner waren, finden zurück zum Code. Probleme mit Kompatibilitäten oder andere versteckte Schwierigkeiten sind im Auswahlprozess sichtbar.
Von Vorarbeit zu kontinuierlicher Begleitung
Architekturarbeit beinhaltet Überlegungen zu technischen Optionen und Risiken, versucht Erkenntnisse aus Umsetzungsarbeit zu verallgemeinern und so Qualitätsziele zu erreichen. Wenn wir nun hypothesenorientiert arbeiten und potenziell mehrere Optionen parallel verfolgen, wird es wichtiger, kontinuierliches Feedback in Form von Guardrails und Fitness Functions zu etablieren. Statt Lösungen einzuschränken und punktuell manuell zu kontrollieren, entstehen kontinuierliche Leitplanken. Sie machen Vergleiche technischer Alternativen möglich, Qualität neutral bewertbar und dezentral auswertbar. Konkret verwenden wir z. B. Review-Agents, die bei jedem Pull Request Architekturvorgaben prüfen (Schichtung, API-Kommunikation, Pattern- und Technologieverwendung …).
Diese Guardrails kann man mit Fitness Functions wie Performancebenchmarks und Security-Scans ergänzen und so stetig prüfen, ob architektonische Eigenschaften gegeben sind, ohne die Architekturidee selbst zu stark einzuschränken. Jeder generierte Code durchläuft sofort Unit- und Policy-Checks. Agenten, die Varianten erzeugen, stoppen automatisch, wenn Abbruchkriterien verletzt sind. Zusammen mit explizitem Kontext entsteht eine Klammer um AI-unterstützte Lösungen, die uns einen sicheren Umgang mit AI-Werkzeugen ermöglicht, ohne zu viel Entwicklungsgeschwindigkeit zu rauben.
Neue Wege für klassische Architekturaufgaben
Die drei Verschiebungen – expliziter Kontext, parallele Experimente, kontinuierliche Guardrails – verändern Architekturarbeit. Sie wird kleinteiliger, experimenteller, automatisierter. Gleichzeitig verschieben sich auch Informationen wie Architekturmuster, Qualitätsziele oder Prinzipien „weicher“ Dokumente wie Wikis im systematischen Kontext für LLMs. Architekturkonzepte haben so gesichert Auswirkungen auf die Lösung, müssen aber auch expliziter und genauer beschrieben werden als bisher. Neben diesem Wandel können wir aber auch eher klassische Aufgaben der Architektur mit AI-Werkzeugen unterstützen. Abbildung 3 zeigt einige Ideen dafür.
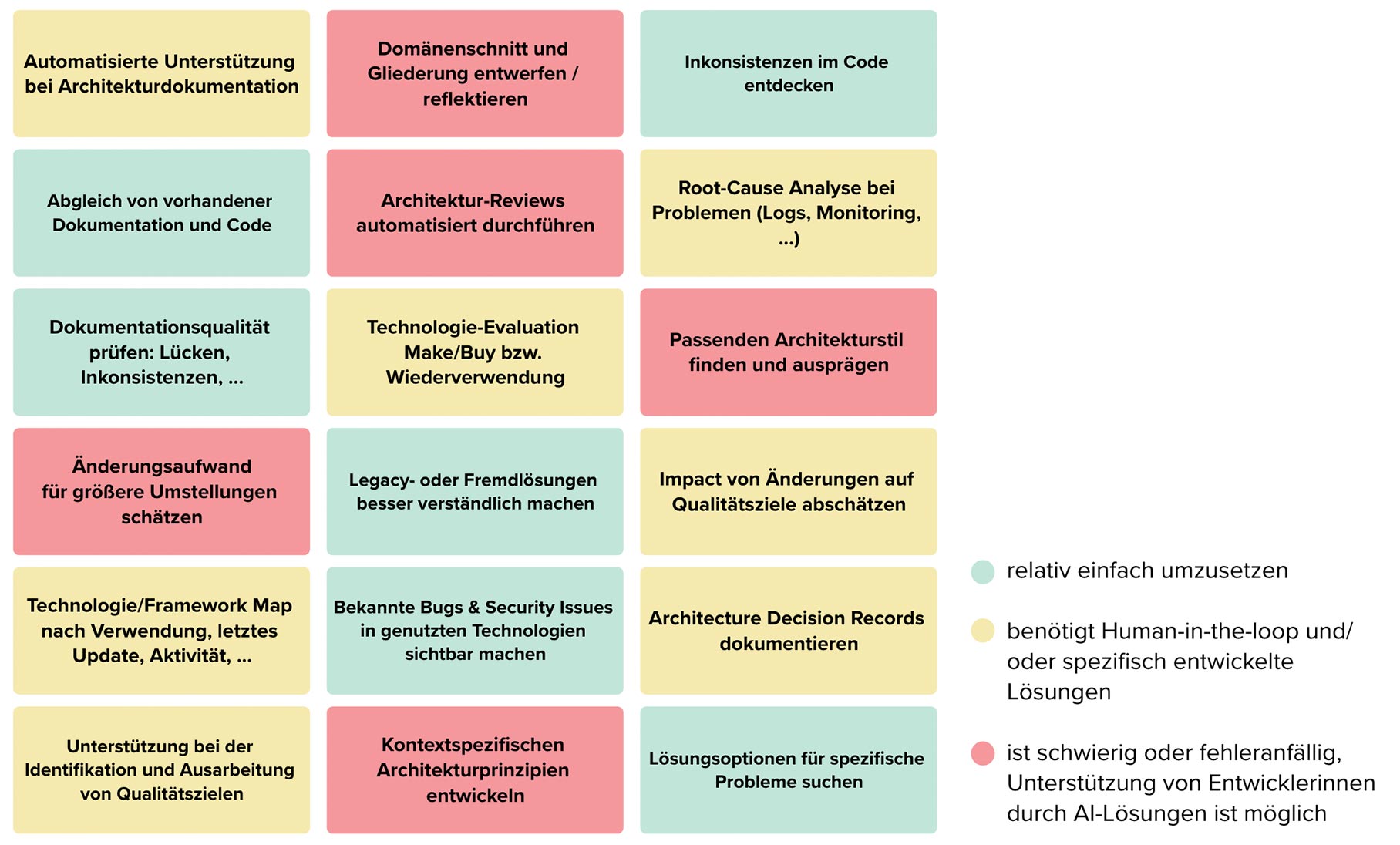
AI Agents sind prädestiniert dafür, die typischen „Metaaufgaben“ der Architektur zu unterstützen, also Aufgaben, die eine übergreifende Sichtweise und Einordnung brauchen. Eine Schwachstelle sind im Moment noch Kategorisierungsaufgaben, in denen etwa Probleme nach ihrer Ähnlichkeit zusammengefasst werden sollen. Selbst dort ist aber die Interaktion mit LLMs und spezifisch orientierten Agents für die Unterstützung der eigenen Gedankengänge hilfreich. Wenn es darum geht, den Lösungsraum zu strukturieren oder technische Optionen zu finden, wird die Unterstützungsleistung besser. Gut funktionieren analytische Agents, die Code, Dokumentation, Konfiguration oder Monitoringdaten als Grundlage verwenden. Damit sind Gap-Analysen, einfachere Dokumentationsaufgaben (die nicht zu sehr abstrahieren) und Reviews oft im Fokus von AI-Architekturinitiativen.
Bei all diesen Möglichkeiten ist jedoch Vorsicht geboten. Nicht jede Architekturaufgabe sollte in Zukunft eins zu eins mit AI Agents ersetzt werden (selbst wenn das ginge). Einige Aufgaben werden sich in Zukunft grundlegend ändern. Nehmen wir z. B. das Thema Architekturdokumentation. In der Vergangenheit haben wir uns darauf fokussiert, Wissen zur Lösung so aufzubereiten, dass es bei zukünftigen Problemen helfen kann. Zum Dokumentationszeitpunkt kennen wir diese Probleme allerdings nicht genau und dokumentieren deshalb eher allgemein. (Alternativ kann auch viel spezifische Dokumentation entstehen, die wegen ihrer Größe dann oft nicht mehr gewartet wird und veraltet.)
So oder so bleibt festzuhalten, dass Dokumentation für ein Problem gebaut wird, das wir noch nicht haben. Ist es eine neue Mitarbeiterin, die einen allgemeinen Überblick braucht? Ist es ein größeres Refactoring, das unser Datenmodell zerpflücken soll? Sind es Performanceprobleme, die unsere Verwendung von Events infrage stellen? Wir wissen es nicht. Mit LLMs und AI Agents sind wir plötzlich in der Lage, zum Zeitpunkt des eigentlichen Problems die richtigen Informationen zusammenzustellen. Wir haben ein Instrument, das viele Informationen kennt – Code, Tickets, Monitoring, vergangene Prompts zur Entwicklung usw. Statt den Umweg über bekannte Dokumentationstemplates zu gehen, bietet es sich hier an, eher Context Engineering für das LLM zu betreiben und ein Unterstützungswerkzeug für die Problemlösung zu schaffen. Manuell erstellte Architekturdokumentation reduziert sich eher auf vereinfachende Übersichten, die in ihrer Knappheit leicht zu pflegen sind und ohnehin nicht im Sweet Spot momentaner LLMs liegen.
Flow und Vibe kaputt?
In diesem Artikel haben wir den Bogen von Vibe Coding und AI-gestützter Entwicklung bis hin zur Architekturdisziplin geschlagen. Schon heute lässt sich beobachten, dass sich klassische Rollen wie Entwicklerinnen und Architektinnen anders verhalten (können), wenn es einen Kontext von AI-unterstützenden Werkzeugen gibt. Doch was macht den Wandel durch AI eigentlich aus? Ist es die rohe Geschwindigkeit der Entwicklung? Ist es zehnfache Produktivität? In der Praxis zeigt sich eher, dass Softwareentwicklung auch mit AI-Unterstützung ein tiefes Engineering-Feld bleibt.
Softwarearchitektur erlebt eine Verschiebung hin zu kontinuierlicher, expliziterer Architekturarbeit, die parallele Experimente unterstützt. Bei richtigem Tooleinsatz und Vorgehen bremst das alles wenig, verschafft aber etwas mehr Überblick und Zielrichtung.
Stay tuned
Immer auf dem Laufenden bleiben! Alle News & Updates:
Links & Literatur
[1] https://github.com/Wirasm/PRPs-agentic-eng
[2] https://github.com/ruvnet/claude-flow
[3] https://github.com/coleam00/Archon
[4] https://docs.anthropic.com/en/docs/claude-code/devcontainer
[5] https://www.philschmid.de/context-engineering
🔍 Frequently Asked Questions (FAQ)
1. Was verändert sich durch AI-Werkzeuge in der Softwareentwicklung?
AI-Werkzeuge wie Coding-Assistenten, Agent-Frameworks oder LLM-Plug-ins beschleunigen viele Entwicklungsprozesse erheblich. Prototypen entstehen schneller, Varianten lassen sich leichter testen, und Architekturentscheidungen können datenbasiert überprüft werden.
2. Was bedeutet „Vibe Coding“?
„Vibe Coding“ beschreibt eine spontane, oft unstrukturierte Nutzung von AI-Tools beim Programmieren – meist über Chatinterfaces oder IDE-Integrationen. Entwickler:innen folgen dabei eher dem Flow und setzen Lösungen pragmatisch um, statt formale Architekturprozesse zu befolgen.
3. Welche neuen Ansätze gibt es für AI-gestützte Softwareentwicklung?
Zu den neuen Paradigmen zählen Conversational Programming, Prompt-Driven Development (PDD) und Agentic Development. Diese Methoden ermöglichen es, Code und Systeme durch Dialog, Prompts oder autonome Agents zu entwickeln und zu orchestrieren.
4. Was ist „Context Engineering“ und warum ist es wichtig?
Context Engineering beschreibt die bewusste Gestaltung maschinenlesbarer Kontexte für AI-Tools. Architekturprinzipien, Qualitätsregeln und Teamkultur werden explizit hinterlegt, damit LLMs und Agents bessere, konsistente Ergebnisse liefern können.
5. Wie verändern AI-Tools die klassische Architekturarbeit?
Architekturarbeit wird iterativer und datengetriebener. Statt einmaliger Vorarbeit steht heute eine kontinuierliche Begleitung mit Guardrails, Fitness Functions und automatisierten Architekturprüfungen im Fokus. Das schafft Qualitätssicherung bei hoher Umsetzungsgeschwindigkeit.
6. Welche Chancen bieten parallele Experimente in der Architektur?
Mit AI-Unterstützung können Architekt:innen mehrere Lösungsvarianten parallel implementieren und testen. So entstehen belastbare Vergleiche auf Basis echter Performance- und Qualitätsdaten, statt rein theoretischer Annahmen.
7. Wer profitiert besonders von AI-gestützter Architekturarbeit?
Vor allem Softwarearchitekt:innen, Entwickler:innen und DevOps-Teams profitieren: Sie können effizienter planen, schneller experimentieren und fundiertere Entscheidungen treffen. Auch Organisationen gewinnen, da Wissen strukturierter und reproduzierbarer wird.



