
Schon Mitte der 1990er Jahre definierten L. Peter Deutsch und Kollegen die „Fallacies of Distributed Computing“ und stellten darin klar: Das größte Hindernis für die Planung und den Betrieb verteilter Systeme sind falsche Annahmen bezüglich der Netzwerkinfrastruktur [1]. Nun leben wir natürlich nicht mehr in einer Zeit, in der wir Rechner über Koaxialkabel und T-Stücke vernetzen und Probleme durch marode Abschlusswiderstände entstehen können [2]. Dennoch gilt es, einige Fallstricke zu beachten, wenn man eine stabile Netzwerkbasis für Microservices-Architekturen erstellen will.
Eine der „Fallacies of Distributed Computing“, also Fehlannahme, lautet: „Die Netzwerktopologie wird sich nicht ändern“. Bei verteilten Systemen ist damit nicht die Topologie der Netzwerkkomponenten untereinander, sondern die IP-Adressierung und Skalierung der Dienste an sich gemeint. In klassischen privaten Rechenzentren ist die Erweiterung der Kapazität von Diensten mit dem zeitaufwendigen Einkauf, Einbau und der Inbetriebnahme von physikalischer Rechenleistung verbunden. Die IP-Adressierung kann daher relativ statisch gehalten werden, sodass in der Regel feste IP-Adressen für die Serversysteme verwendet werden.
In der Cloud hingegen ist das nicht mehr möglich: Dienste wachsen und schrumpfen sehr dynamisch, meistens auch automatisch. Das bringt uns zum ersten von zwei stark verknüpften Themen: dem Ermitteln der IP-Adressen, über die die Dienste erreichbar sind (Service Discovery), sowie der Lastverteilung von dynamisch skalierenden Diensten (Load Balancing).
An dieser Stelle drängt sich vielleicht die Frage auf: Warum nicht DNS nutzen? Ist es nicht genau die Aufgabe von DNS, Hostnamen zu IP-Adressen aufzulösen? Und DNS kann schließlich mehrere IPs in Form von multiplen A-Records für einen Namen zurückliefern!
Das ist zwar richtig, allerdings gibt es bei der Verwendung von DNS mehrere Probleme: DNS ist für die Größe des Internet gebaut. Die Replizierung von DNS-Einträgen über reguläre DNS-Zonen-Transfers sowie das automatische Entfernen von Caching-Einträgen ist für den Einsatz in sehr dynamischen Umgebungen zu langsam. Zudem ist es schwieriger, Metadaten für die Hostnamen im DNS-System zu speichern und abzufragen. Zwar verfügt DNS über die Record Types SRV und TXT, um Metadaten wie TCP/UDP-Ports und beliebigen Text zu speichern. Clients können aber nicht spezifisch nach Records fragen, die bestimmte Metadaten enthalten. Ein Bespiel in der AWS-Cloud könnte sein, nach Instanzen zu suchen, die sich in einer bestimmten Availability-Zone befinden und nur die IP-Adressen (A-Records) zurückzuerhalten, die sich dort befinden.

Systeme modernisieren statt nur migrieren
Power-Workshops zu Modernisierung & Service-Architektur (22. - 26. Juni 2026, München)
Service Discovery und Load Balancing
Service Discovery und Load Balancing können sowohl client- als auch serverseitig implementiert werden. Der clientseitige Ansatz stellt eine verteilte Datenbank als Service Registry in den Mittelpunkt (Abb. 1). Die einzelnen Serverkomponenten, im Folgenden auch Targets genannt, registrieren sich bei der Service Registry und halten diese Registrierung durch Heartbeat-Methoden aufrecht. Manche Service-Discovery-Systeme erwarten von den Targets als Heartbeat eine regelmäßige Neuregistrierung, andere sind in der Lage, sie aktiv auf ihre Funktionsfähigkeit zu prüfen, beispielsweise durch HTTP-Testanfragen. Zur Nutzung eines Dienstes fragt ein Client zunächst in der Datenbank eine Liste von Targets mit ihren IP-Adressen und Portnummern ab, die den Dienst anbieten. Hierbei kann der Client auch Metadaten verwenden, um nach bestimmten Eigenschaften der Targets zu filtern, beispielsweise welche Version des Diensts genutzt werden soll. Anschließend ist es die Aufgabe des Clients, seine Anfragen auf die zur Verfügung stehenden Targets zu verteilen.

Häufig wird als Service Registry das Netflix-Eureka-Projekt [3] verwendet, das sehr gut in Spring Cloud [4] integriert ist. Zu nennen sind aber auch HashiCorp Consul [5], Apache Zookeeper [6] sowie Dienste in der Cloud wie der AWS-Cloud-Map-Dienst [7].
Ein Nachteil des clientbasierten Load Balancing ist, dass jeder Client die Verbindung (Session) zu den Targets verwalten muss, was die Clientimplementierung komplizierter macht und Memory-Ressourcen kostet. Auch ist es schwieriger, die Last gleichmäßig auf die Targets zu verteilen, da eine zentrale Sicht auf die bereits aufgebauten Sessions bei diesem Ansatz fehlt.
Das bringt uns zu serverseitigem Service Discovery und Load Balancing. Dabei wird die Verantwortung für den Session-Aufbau sowie die Session-Verwaltung an die Targets und einen vorgeschalteten Load Balancer abgegeben. Die Targets registrieren sich nicht bei der Service Registry, sondern bei einem Load Balancer, der sie in die Liste der Targets für den Dienst aufnimmt und ihren Zustand daraufhin mittels Health Checks überwacht (Abb. 2). Der Vorteil ist, dass die Verwaltung der Sessions vom Load Balancer übernommen wird. Dieser kann über aktives und passives Health Checking den Zustand der Targets überwachen (Kasten: „Aktives und passives Health Checking beim Load Balancer“).
Der Client muss lediglich die IPs des Load Balancer über DNS auflösen und sendet alle Anfragen nur noch an den Load Balancer, der sie dann an die Targets verteilt. Die IPs des Load Balancer selbst sind in der Regel statisch, sodass die langsame DNS-Synchronisation und das DNS-Caching nicht ins Gewicht fallen.

Rein serverseitige Service Discovery und Load Balancing sind jedoch selten geworden. Vielmehr kann heute von infrastrukturseitiger Service Discovery und Load Balancing gesprochen werden. In der AWS Cloud werden beispielsweise die Targets (Server/Instanzen) über Auto-Scaling-Groups dynamisch zum Load Balancer hinzugefügt [8]. Die Registrierung erfolgt also über die Infrastruktur und nicht serverseitig. Gleiches gilt für Kubernetes: Die Kubernetes Pods, bei denen es sich um eine Sammlung von Containern mit gemeinsamer IP-Schnittstelle handelt [9], werden automatisch in die Liste der Kubernetes-Service-Endpunkte aufgenommen, zu denen dann ein Load Balancing erfolgt [10].
Aktives und passives Health Checking beim Load Balancer
Aktives Health Checking
Beim aktiven Health Checking prüft der Load Balancer selbst, ob das Target bereit ist, Anfragen zu verarbeiten. Er sendet zum Beispiel testweise TCP-Verbindungsanfragen oder HTTP Requests und prüft, ob sie erfolgreich beantwortet werden. Um Targets nicht zu überlasten, werden die Anfragen jedoch periodisch und in der Regel mit geringer Frequenz gestellt und Targets werden erst nach mehreren fehlgeschlagenen Anfragen aus der Target-Liste entfernt. Das birgt die Gefahr, dass zwischenzeitliche Anfragen ins Leere laufen.
Passives Health Checking
Hierbei beobachtet der Load Balancer den Verbindungsaufbau oder die HTTP-Anfragen der Clients. Sollte der Load Balancer dabei viele Verbindungsprobleme erkennen, streicht er das betroffene Target von der Liste.
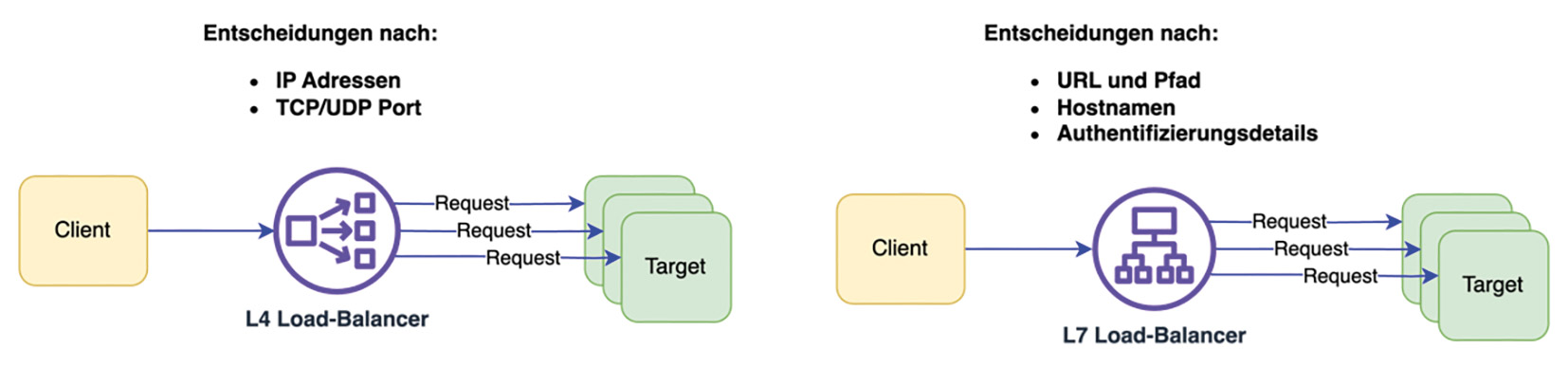
Load Balancing auf Layer 4 und 7
Load Balancer, die auf Layer 4 entscheiden, schauen sich nur TCP- und UDP-Ports an und halten eine Verbindungstabelle, anhand derer entschieden wird, an welches Target Anfragen geschickt werden. Das geschieht sehr schnell, also mit sehr geringer Zeitverzögerung, da diese Entscheidungen entweder in Hardware in Form von ASICs oder FPGAs oder in Software in Form von DPDK-Implementierungen getroffen werden.
Load Balancer und Reverse Proxies, die auf Layer 7 arbeiten, sehen sich Protokolldetails wie beispielsweise HTTP-Header an, um Entscheidungen zu treffen. Oft werden Layer 7 Load Balancer als reine Software-Load-Balancer ausgeführt, und das führt zu einer größeren Zeitverzögerung im Vergleich zu denen von Layer 4.
Der Vorteil von Layer-7-Entscheidungen ist, dass sie mit mehr Anwendungswissen getroffen werden. Zum Beispiel können URL-Pfade und Host-Header verwendet werden, um Target-Gruppen auszuwählen. Darüber hinaus haben diese Layer-7-Load-Balancer-Systeme, die in der Regel softwarebasiert sind, viele Möglichkeiten, Dinge wie Authentifizierung und Autorisierung, Drosselung und tieferes Monitoring anzubieten.
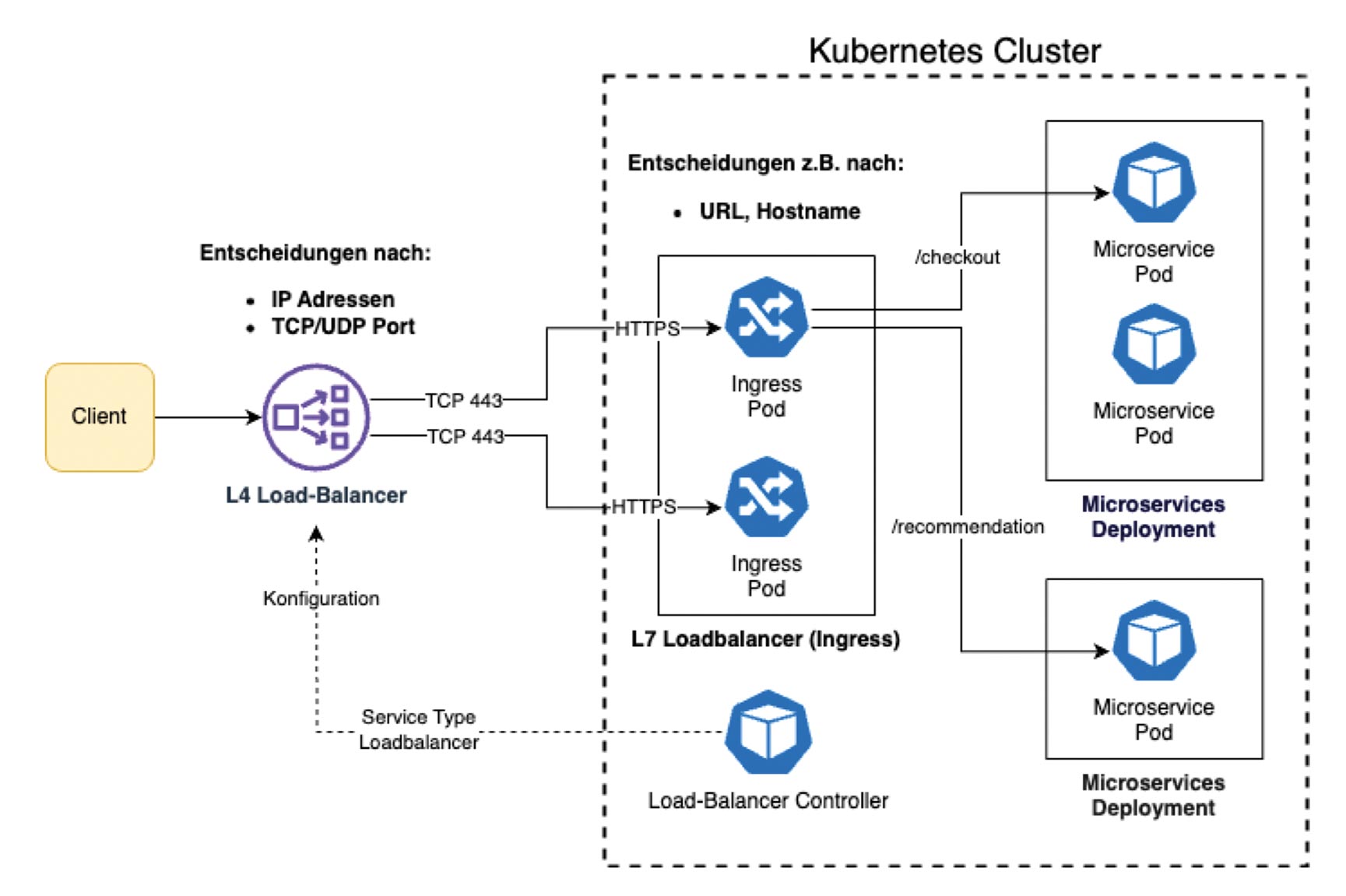
In der Praxis sehen wir oft eine Kombination oder Kette von Load-Balancing-Systemen. So wird in Kubernetes-Umgebungen häufig ein Layer 7 Load Balancing in Software realisiert. Hierfür wurde in Kubernetes das Ingress-Objekt definiert, das als Dataplane Pods verwendet. Um den Netzwerkverkehr überhaupt zum Pool von Ingress Dataplane Pods zu leiten, werden meist Layer 4 Load Balancer eingesetzt. Sie werden in der Regel von Kubernetes-Load-Balancer-Controllern gesteuert, die dann beispielsweise den AWS Network Load Balancer in der Cloud konfigurieren (Abb. 4).
Sicherheit auf der Netzwerkebene
Eine weitere falsche Annahme ist, dass das Netzwerk sicher ist. Wir müssen leider davon ausgehen, dass Angreifer in der Lage sind, Systeme in unserem Netzwerk zu übernehmen, um von dort aus Angriffe zu starten. Das gilt natürlich auch für die Clients und Server in unserer Microservices-Architektur. Es muss verhindert werden, dass ein Angreifer, der sich Zugang zu einem System verschafft hat, sich lateral in unserem Netzwerk bewegen und weitere Systeme angreifen und unter seine Kontrolle bringen kann. Daher ist es wichtig, dass nur die benötigten TCP/UDP-Ports geöffnet werden, die für die Kommunikation der Anwendung notwendig sind.
In klassischen privaten Rechenzentren mit ihrer statischen IP-Adressierung konnte das noch über zentrale Firewall-Systeme erfolgen. Die IP-Adresse wurde hier als feste Identität für den Client oder den Server angenommen. In der Cloud und in Containerumgebungen wie Kubernetes wird das zunehmend schwieriger bis unmöglich. IP-Adressen stammen aus größeren dynamischen IP-Bereichen und liegen gerade bei Kubernetes meist hinter einer NAT-Grenze (Kasten: „NAT-Grenzen von Kubernetes-Clustern“).
Um auch in diesen dynamischen Umgebungen nur die benötigten TCP/UDP-Ports offenzuhalten, muss die Firewall näher an die Clients und Server gebracht werden. Das geschieht in Form von verteilten Paketfiltern wie beispielsweise AWS Security Groups [11], Kubernetes Network Policy [12] oder VMware NSX Distributed Firewall [13], um nur einige Beispiele zu nennen. Die jeweilige Steuerungsebene (Control Plane) der Infrastrukturumgebung kann nun anhand von Gruppenzugehörigkeiten und Metadaten (beispielsweise Tags/Labels) der Clients und Server Paketfilterentscheidungen treffen. Als Beispiel seien hier die AWS Security Groups genannt, die den Instanzen (Targets/Server) in Auto-Scaling-Groups zugeordnet werden. Damit ist es möglich, die Kommunikation zwischen automatisch skalierenden Clients und Servern über deren Gruppenzugehörigkeit zu regeln, anstatt sich auf statische IP-Adressen und IP-Adressbereiche zu verlassen.

NAT-Grenzen von Kubernetes-Clustern
Network Address Translation (NAT) bezeichnet den Prozess des Ersetzens von Quell- oder Ziel-IP-Adressen in IPv4-Paketen, wenn diese Netzwerkgrenzen überschreiten. Am bekanntesten ist die Umwandlung von privaten IPv4-Adressen in öffentlich im Internet bekannte IPv4-Adressen, wie sie in jedem Heimrouter bei uns zu Hause vorkommt.
Kubernetes wurde so konstruiert, dass jedem Pod [9] eine eigene IP-Adresse zugeordnet wird. Das Kubernetes-Netzwerkmodell erfordert, dass jeder Pod jeden anderen Pod über seine IP-Adresse erreichen kann. Das ist eine elegante Lösung für das Problem von TCP/UDP-Port-Konflikten in Umgebungen, in denen Container einen Host gemeinsam nutzen. Da jeder Pod seine eigene IP besitzt, dürfen sich die Portnummern der Pods/Container auf dem gleichen Host (Kubernetes Node) überschneiden.
Den Pods werden IP-Adressen aus großen IP-Bereichen zugewiesen, was im Wesentlichen bedeutet, dass jedem Anwendungsprozess eine IP-Adresse zugeordnet wird. Bei einer großen Anzahl von Pods entstehen aber schnell Probleme aufgrund des knappen IPv4-Adressraums. Daher werden die Pods meist in gekapselten Netzwerken innerhalb der Kubernetes-Umgebung gehalten. Damit die Pods nach außen kommunizieren können, müssen ihre Adressen mittels NAT umgewandelt werden. Um von außen erreichbar zu sein, werden Load Balancer eingesetzt, die ebenfalls NAT verwenden, um den Verkehr an die Pods zu leiten. Das kann als NAT-Grenze von Kubernetes-Clustern bezeichnet werden.
Authentisierung, Authentifizierung, Autorisierung und Verschlüsselung
Bei der Authentisierung, Authentifizierung und Autorisierung sollte zwischen der externen Netzwerkkommunikation und der internen Kommunikation zwischen Diensten innerhalb der Microservices-Architektur unterschieden werden.
Für externe API-Anfragen wird üblicherweise OAuth 2.0 [15] verwendet. Wenn Nutzer beteiligt sind, wird meist Open ID Connect (OIDC) [16] verwendet, das auf OAuth 2.0 aufbaut. Die Autorisierung erfolgt dann anhand von in der Authentisierung mitgelieferten Metadaten, meist in Form von JSON Web Tokens (JWT) [17]. Die Authentifizierung kann am ersten Load Balancer oder API Gateway in der Kette erfolgen, der bzw. das die Metadaten in JWTs weiterleitet, sodass in der Applikation Autorisierungsentscheidungen getroffen werden können. OAuth 2.0 und OIDC ermöglichen eine sitzungsbasierte Authentifizierung und Autorisierung. Andere Methoden, wie zuvor ausgetauschte API Keys oder Mutual-TLS-(mTLS-)Authentisierung mit Zertifikaten, bei dem der Client und der Server sich gegenseitig überprüfen, sind ebenfalls möglich.
Die interne API-Kommunikation zwischen den Clients und Targets innerhalb der Microservices-Umgebung geschieht häufig ohne Authentifizierung und Autorisierung. Hier wird oft angenommen, dass die Sicherheit auf Netzwerkebene durch Firewalls oder Paketfilter gegeben ist. Wie jedoch bereits im Kapitel über die Sicherheit auf Netzwerkebene erwähnt, ist die Identität, die uns eine IP-Adresse bietet, sehr schwach, da sich IP-Adressen schnell ändern können. Daher ist es wünschenswert, auch die gesamte interne API-Kommunikation mit besseren Mitteln abzusichern. Da an der internen API-Kommunikation keine Benutzer beteiligt sind und in der Regel keine sitzungsbasierte Authentifizierung und Autorisierung erforderlich ist, werden zu ihrer Sicherung in der Regel API Keys oder die gegenseitige (mutual) TLS-Authentifizierung verwendet.
Meist wird das Thema Verschlüsselung in einem Atemzug mit Authentifizierung und Autorisierung genannt. Das ist teilweise richtig, beispielsweise, wenn mTLS verwendet wird. In diesem Fall erfolgt die Authentisierung über Zertifikate beim TLS Handshake. Die Autorisierung geschieht dann über Metadaten in den Zertifikaten. Es ist aber durchaus möglich, die Verschlüsselung auf Infrastrukturebene zu lösen, ohne eine Authentifizierung und Autorisierung bei den Diensten durchzuführen. So gibt es im Bereich Kubernetes Netzwerklösungen, die eine Verschlüsselung zwischen den Kubernetes Nodes mit IPSec [18] oder WireGuard [19] anbieten, unter anderem mit dem Cilium CNI [20]. Die gebräuchlichste Methode ist jedoch sicherlich die Verwendung von TLS für die gesamte externe und interne Kommunikation. Auch beim Einsatz von TLS kann das Thema Verschlüsselung von der Authentifizierung und Autorisierung getrennt werden. In diesem Fall wird nur der Server über sein Zertifikat authentifiziert, der Client wird weder authentifiziert noch autorisiert.
Synchrone oder asynchrone Microservices-Kommunikation
Dem mit Microservices vertrauten Leser wird aufgefallen sein, dass ich bisher nicht darauf eingegangen bin, dass Microservices sowohl direkt und synchron als auch indirekt und asynchron miteinander kommunizieren können, also beispielsweise über Messages, Queues, Streams, Files und Datenbankobjekte.
Die Verwendung von Diensten für die asynchrone Kommunikation ist in der Regel einfacher als der Aufbau von Strukturen für synchrone APIs, die ich bisher in diesem Artikel behandelt habe. In den meisten Fällen werden Cloud-Dienste verwendet, sodass die Clients lediglich einen DNS-Namen für den Dienst auflösen und mit der oder den zurückgelieferten IP-Adressen kommunizieren.
Ambassador- und Sidecar-Patterns
Grundsätzlich kann gesagt werden, dass das Ambassador- und das Sidecar-Pattern eine Mischung aus client- und serverseitigem Ansatz darstellen. Insbesondere wird der Clientcode von Aufgaben wie mTLS-Authentifizierung und Autorisierung, Load Balancing, Netzwerkmonitoring, Logging und Tracing befreit. Diese Aufgaben werden in einen separaten Prozess ausgelagert, der auf dem gleichen Host läuft – oder im Fall von Kubernetes als weiterer Container im Pod.
Als Ambassador oder Sidecar wird meist ein Reverse Proxy wie Envoy [21] verwendet, der häufig zentral verwaltet wird. Lösungen für dieses Problem werde ich im zweiten Teil dieser Serie behandeln, in dem es unter anderem um Service-Mesh-Lösungen gehen wird.
Fazit
Im ersten Teil unserer Serie haben wir uns mit den Grundlagen des Netzwerkdesigns für Microservices-Architekturen beschäftigt. Das nächste Mal werden wir uns anschauen, wie die bisher behandelten Kernthemen Service Discovery, Load Balancing, Netzwerksicherheit sowie Authentifizierung, Autorisierung und Verschlüsselung in Lösungen umgesetzt werden. Dabei werden Frameworks wie Spring Cloud, aber auch Cloud-Lösungen im Allgemeinen sowie die Netzwerklösungen innerhalb von Kubernetes und Service Meshes betrachtet.
Links & Literatur
[1] https://de.wikipedia.org/wiki/Fallacies_of_Distributed_Computing
[2] https://de.wikipedia.org/wiki/10BASE2
[3] https://github.com/Netflix/eureka/wiki
[4] https://spring.io/projects/spring-cloud
[5] https://developer.hashicorp.com/consul/docs/concepts/service-discovery
[7] https://aws.amazon.com/cloud-map/
[8] https://docs.aws.amazon.com/autoscaling/ec2/userguide/autoscaling-load-balancer.html
[9] https://kubernetes.io/docs/concepts/workloads/pods/
[10] https://kubernetes.io/docs/concepts/services-networking/service/
[11] https://docs.aws.amazon.com/vpc/latest/userguide/security-groups.html
[12] https://kubernetes.io/docs/concepts/services-networking/network-policies/
[13] https://www.vmware.com/products/nsx-distributed-firewall.html
[14] https://aws.amazon.com/waf/features/
[15] https://oauth.net/2/
[16] https://openid.net
[17] https://jwt.io
[18] https://de.wikipedia.org/wiki/IPsec
[19] https://de.wikipedia.org/wiki/WireGuard
[20] https://docs.cilium.io/en/latest/security/network/encryption-wireguard/



